
Clasificación de imágenes (rayos x) de Tórax con Deep Learning
- siria sadeddin

- Apr 15, 2020
- 7 min read
Updated: Apr 25, 2020
Hola! 👩💻
Hoy les contaré como hacer clasificación de imágenes con Deep Learning, haciendo uso de la arquitectura VGG16 con Tranfer Learning.
Para este ejemplo usaré la base de datos de kaggle "Chest X-Ray Images (Pneumonia)" que contiene 5863 imágenes de rayos X de tórax divididos en 2 categorías: Normal y Pneumonia.
El link a la base de datos es el siguiente:

La neumonía es una infección de uno o los dos pulmones. Muchos gérmenes, como bacterias, virus u hongos, pueden causarla. También se puede desarrollar al inhalar líquidos o químicos. Las personas con mayor riesgo son las mayores de 65 años o menores de dos años o aquellas personas que tienen otros problemas de salud (https://medlineplus.gov/spanish/pneumonia.html).
La imagenología juega un papel fundamental como pilar diagnóstico en las neumonías a través, fundamentalmente, del par radiográfico del tórax (frente y perfil), que permite identificar patrones habitualmente correlacionables con las distintas causas, hecho que, sin ser definitivo, permite sugerir una orientación terapéutica, aunque no en forma aislada. (http://www.scielo.edu.uy/scielo.php?script=sci_arttext&pid=S1688-12492002000100004).
Nuestro objetivo será entrenar un modelo de Red Neural Convolucional que permita establecer si existe o no neumonía en el paciente, a partir de sus imágenes radiológicas de tórax.
Nuestro plan de trabajo es el siguiente:
1) Descarga y extracción de datos
2) Análisis y visualización de datos
3) Aumento de datos a través de pequeñas modificaciones a las imágenes
4) Creación de conjuntos de entrenamiento, prueba y validación.
5) Creación de modelo de Deep Learning Convolucional importando la arquitectura VGG16 para Transfer Learning.
6) Entrenamiento del modelo.
7) Estudio de las métricas del modelo para validar su eficiencia.
Descarga y extracción de datos
La descarga de los datos se hizo directamente a un cuaderno de Google Colab siguiendo las instrucciones que puedes encontrar en mi post "Cómo cargar datasets de Kaggle en Google Colab"
Recuerda, aquí debes subir el archivo .json de tu cuenta Kaggle
!pip install -U -q kaggle
!mkdir -p ~/.kaggle
from google.colab import files
files.upload()!cp kaggle.json ~/.kaggle/!kaggle datasets download -d paultimothymooney/chest-xray-pneumoniaUna vez que los datos están descargados debemos extraerlos ya que se encuentran comprimidos en un archivo .zip
from zipfile import ZipFile
import glob
zip_file = ZipFile('/content/chest-xray-pneumonia.zip')
#opening the zip file in READ mode
with ZipFile('/content/chest-xray-pneumonia.zip', 'r') as zip:
# extracting all the files
print('Extracting all the files now...')
zip.extractall()
print('Done!')
!cd /contentVamos a trabajar con imágenes y redes de aprendizaje profundo, en este caso lo mejor es que cambies la configuracion de Google Colab a un entorno de ejecución con acelerador de hardware GPU. Esto te permitirá entrenar los modelos mucho mas rápido.

Definamos variables que contienes los paths de cada uno de los directorios con los que vamos a trabajar. Esto puede ser de ayuda para la exploración de datos, ya que después no tendremos que recordar explícitamente la dirección del path que queremos invocar.
Definiremos otras variables que guardaran los nombres de los archivos contenidos en los directorios de entrenamiento, prueba y validación.
La librería "os" de python es de gran ayuda cuando queremos trabajar con directorios.
import os
#path to Colab main directory
base_dir = '/content/'
#path to image data directory
data_dir = os.path.join(base_dir, 'chest_xray')
#path to image train, test and validation directories
train_dir = os.path.join(data_dir, 'train')
test_dir = os.path.join(data_dir, 'test')
val_dir = os.path.join(data_dir, 'val')
#path to train normal and pneumonia images
train_normal_dir = os.path.join(train_dir, 'NORMAL')
train_pneu_dir = os.path.join(train_dir, 'PNEUMONIA')
#path to test normal and pneumonia images
test_normal_dir = os.path.join(test_dir, 'NORMAL')
test_pneu_dir = os.path.join(test_dir, 'PNEUMONIA')
#path to validation normal and pneumonia images
val_normal_dir = os.path.join(val_dir, 'NORMAL')
val_pneu_dir = os.path.join(val_dir, 'PNEUMONIA')
#list of files names for images in train normal and pneumonia folders
list_train_pneu = os.listdir(train_pneu_dir)
list_train_normal = os.listdir(train_normal_dir)
#list of filess names for images in test normal and pneumonia folders
list_test_pneu = os.listdir(test_pneu_dir)
list_test_normal = os.listdir(test_normal_dir)
#list of files names for images in validation normal and pneumonia folders
list_val_pneu = os.listdir(val_pneu_dir)
list_val_normal = os.listdir(val_normal_dir)Exploración de los datos
Siempre es bueno empezar por explorar un poco nuestros datos para conocer el ambiente en el que estamos trabajando. Esto nos puede permitir hacer mejoras futuras y tener ideas nuevas para nuestros modelos.
Lo primero que haremos será ver la distribución de cantidad de imágenes con diagnóstico de neumonía y normales.
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
plt.bar([1,2],np.array([len(list_train_pneu),len(list_train_normal)]),color=['gray','purple'], alpha=0.5)
plt.title('Neumonia vs normal training')
plt.xticks([1,2],('Neumonia','normal'))
plt.ylabel('Count')
pd.DataFrame({'percentage':np.array([len(list_train_pneu),len(list_train_normal)])/sum([len(list_train_pneu),len(list_train_normal)])})
Como se observa en gráfico de barras a la izquierda, nuestros datos presentan un desbalance entre la cantidad de imágenes de pacientes diagnosticados con neumonía y normales.
Esto puede representar un problema a la hora de entrenar nuestro clasificador, ya que el modelo puede acabar teniendo preferencia sobre la clase con mayor cantidad de imágenes. En estos casos existe la opción de hacer upsampling o downsampling.
Para hacer upsamplig, se requiere tomar aleatoriamente las imágenes disponibles en el dataset mas pequeño y modificarlas un poco para de esta manera crear "nuevas imágenes" artificialmente. Las modificaciones pueden ser por ejemplo en iluminación, posición, contraste, rotación, etc; agregar una imagen exactamente igual a la que ya está en nuestro conjunto de imágenes no añadiría valor a la estadística del modelo.
No haré upsampling para este primer caso, ya que lleva más tiempo y consumo de recursos a la hora de entrenar el modelo. Quiero enfocarme primero en la construcción y validación de las arquitecturas de Red Neural más efectivas para la clasificación, una vez hecho esto, es interesante intentar aumentar la cantidad de datos haciendo upsampling y ver si mejora el accuracy.
Explorando los datos para prueba y validación vemos que existe el mismo desbalance de datos en el conjunto de prueba, mientras que el conjunto de validación se encuentra balanceado con 8 imágenes para cada clase.

Balanceo de datos
En esta sección nos dedicaremos a balancear nuestro conjunto de datos usando el método de downsampling. Este método consistirá en tomar de forma aleatoria imágenes del conjunto que contiene mayor cantidad de imágenes (neumonía) hasta completar la misma cantidad de ejemplos que contiene el conjunto con menos imágenes (normal). Necesitaremos la librería "random" de python para este proceso.
import random
train_path =train_pneu_dir
train_files = os.listdir(train_path)
train_down = random.sample(train_files,len(list_train_normal))
test_path =test_pneu_dir
test_files = os.listdir(test_path)
test_down = random.sample(test_files,len(list_test_normal))El código anterior a tomado aleatoriamente los nombres de los archivos en las carpetas que contienen las imágenes en train y test con "neumonía" hasta completar la misma cantidad en train y test "normal" respectivamente. Ahora crearemos nuevas carpetas para train y test que llamaremos "train_down" y "test_down" para guardar nuestros datos balanceados.
os.chdir(data_dir)
os.mkdir('train_down')
os.mkdir('test_down')
train_down_dir=os.path.join(data_dir,'train_down')
test_down_dir=os.path.join(data_dir,'test_down')
os.chdir(train_down_dir)
os.mkdir('PNEUMONIA')
os.mkdir('NORMAL')
os.chdir(test_down_dir)
os.mkdir('PNEUMONIA')
os.mkdir('NORMAL')Usaremos la librería "shutil" para copiar los archivos desde sus carpetas originales hasta las nuevas carpetas que hemos creado para los datos balanceados.
import shutil
train_pneu_down_dir=os.path.join(train_down_dir, 'PNEUMONIA')
os.chdir(train_pneu_dir)
for i in train_down:
shutil.copy(i,train_pneu_down_dir)
train_normal_down_dir=os.path.join(train_down_dir, 'NORMAL')
os.chdir(train_normal_dir)
for i in list_train_normal:
shutil.copy(i,train_normal_down_dir)
test_pneu_down_dir=os.path.join(test_down_dir, 'PNEUMONIA')
os.chdir(test_pneu_dir)
for i in test_down:
shutil.copy(i,test_pneu_down_dir)
test_normal_down_dir=os.path.join(test_down_dir, 'NORMAL')
os.chdir(test_normal_dir)
for i in list_test_normal:
shutil.copy(i,test_normal_down_dir)Solo por comprobar que nuestro procedimiento se completó de forma correcta graficaremos de nuevo la cantidad de datos en nuestras carpetas de downsampling.

Bien!! nuestros datos están balanceados 🤪
Exploración de imágenes
Creo que si estamos trabajando con imágenes, a todos nos gustaría saber como se ven esas imágenes. Además, observar las imágenes nos permitirá decidir si éstas son de buena calidad, si corresponden al objetivo de estudio, si son consistentes en tamaño u otras características. Usaremos Opencv (cv2) para esta fase, es una librería que nos permite manipular imágenes.
import cv2
%matplotlib inline
gamma = 3
filename = train_normal_dir + '/' + str(list_train_normal[1])
# load image pixels
img = cv2.imread(filename)
corrected_image = np.power(img, gamma)
plt.imshow(img)
Esta imagen corresponde al los rayos X de tórax de un paciente sano o "normal" en nuestros datos. Veamos algunos casos extra para pacientes con "neumonía" y normales.
import numpy as np
%matplotlib inline
for i in range(9):
# define subplot
plt.subplot(330 + 1 + i)
# define filename
filename = train_pneu_dir + '/' + str(list_train_pneu[i])
# load image pixels
img = cv2.imread(filename)
# plot raw pixel data
img=cv2.resize(img,(200,200))
plt.imshow(img,cmap='gray')
plt.axis('off')
# show the figure
plt.show()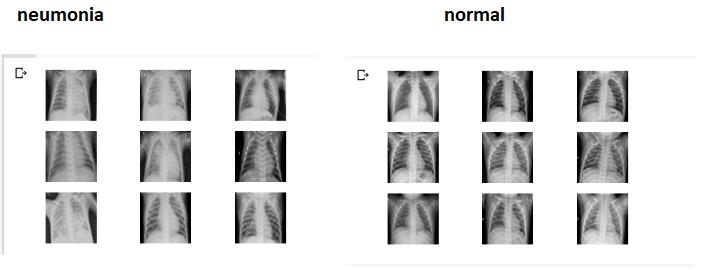
A simple vista se puede apreciar las diferencias en las imágenes, los pacientes "normales" generalmente tienen la zona torácica "limpia" mientras que las personas con "neumonía" presentan opacidad en el área de los pulmones.
Podríamos asumir a partir de estas imágenes que es posible entrenar un modelo de Machine Learning, en este caso Red Convolucional, que permita hacer un diagnostico automático de la patología.
Creación del modelo
Keras tiene funcioncionalidades super útiles para cargar datos de imágenes desde carpetas, usaremos esta librería para crear nuestro modelo
Primero cargaremos las imágenes como conjuntos de datos para entrenamiento, prueba y validación. La función "ImageDataGenerator" nos permitira realizar un proceso llamado "aumento de datos" este proceso permite aumentar la cantidad de imágenes en el entrenamiento, mediante pequeñas modificaciones a las imágenes originales (rotación, movimiento a la derecha, izquierda, arriba, abajo, acercar, alejar, brillo, etc) además permite la normalización de la escala de colores desde el rango (0,255) a el rango (0,1). Este proceso es diferente al upsampling ya que el aumento de los datos se hace sobre todo el conjunto de datos, no sobre una clase en específico. Aplicaremos la función "ImageDataGenerator" a los conjuntos de entrenamiento, prueba y validación.
Pero CUIDADO! no se debe hacer aumento de datos a los conjuntos de validación y pruebas, ya que queremos validar nuestro modelo sobre las imágenes originales. Validar sobre imágenes modificadas nos dará un resultado viciado.
# create data generator
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
datagen_train = ImageDataGenerator(rescale=1.0/255.0,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
fill_mode='nearest',
zoom_range=0.2,
brightness_range=[0.9, 1.1]
)
datagen_test = ImageDataGenerator(rescale=1.0/255.0)
datagen_val = ImageDataGenerator(rescale=1.0/255.0)Con la funciona "flow_from_directory" aplicaremos los cambios requeridos en el código anterior sobre las imágenes en las carpetas de entrenamiento, prueba y validación respectivamente.
Sobre esta función les tengo que decir algunos detalles importantes:
1) El "flow_from_directory" de entrenamiento y prueba deben ser exactamente iguales, salvo por el directorio de origen.
2) Debemos colocar Shuffle=True para entrenamiento y prueba, esto es SUPER SUPER importante ya que estamos entrenando el modelo con secciones de datos llamados batch, si los datos no están "barajados" apropiadamente, el modelo se entrenará con clases poco balanceadas en cada batch, lo que le impedirá encontrar el mínimo global de la función de costo.
3) Para poder hacer la predicción sobre el conjunto de validación debemos poner el batch_size=1 y el class_mode debe ser "None".
4) El seed lo he colocado por reproducibilidad del trabajo.
# prepare iterators
batch_size=64
train_it = datagen_train.flow_from_directory(train_down_dir,
class_mode='categorical', batch_size=batch_size,shuffle=True, target_size=(224, 224),color_mode="rgb",seed=42)
test_it = datagen_test.flow_from_directory(test_down_dir,
class_mode='categorical', batch_size=batch_size,shuffle=True, target_size=(224, 224),color_mode="rgb",seed=42)
val_it = datagen_val.flow_from_directory(val_dir,batch_size=1,class_mode=None,shuffle=False, target_size=(224,224),color_mode="rgb",seed=42)
Found 2682 images belonging to 2 classes.
Found 468 images belonging to 2 classes.
Found 468 images belonging to 2 classes.
Found 16 images belonging to 2 classes.Para la arquitectura del modelo he usado Tranfer Learning de Arquitectura VGG16, pero ustedes son libres de usar cualquier otra arquitectura de preferencia, de hecho yo intentaré algunas otras en el futuro para ver si se puede mejorar el modelo.
from tensorflow.keras.applications.vgg16 import VGG16
conv_base = VGG16(weights="imagenet",include_top=False,input_shape=(224, 224, 3))
print(conv_base.summary())Para tener libertad de elegir la cantidad de pixeles de entrada en la red hemos colocado include_top=False.
A esta arquitectura le agregaré las capas finales, definiendo la activación de la última capa "softmax" la cual es apropiada para clasificación de dos salidas como la nuestra, y loss= "categorical_crossentropy" , como optimizador he usado Adam ya que este resulta ser mejor para muchos casos. He agregado una capa de 200 neuronas (después de muchas pruebas) encontrando que esta cantidad da buenos resultados. Las capas de dropout permiten evitar el overfiting.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras import regularizers, losses, metrics
from tensorflow.keras.optimizers import Adam
model = Sequential()
model.add(conv_base)
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(200, activation='relu',kernel_regularizer=regularizers.l2(0.001)))
model.add(Dropout(0.2))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer=Adam(lr=0.0001),
loss='categorical_crossentropy',
metrics=['accuracy'])
print("model compiled")
print(model.summary())El "learning rate" es crucial en todo entrenamiento, pero escoger el adecuado puede ser tedioso, ya que tendríamos que efectuar iteraciones hasta encontrar el óptimo.
El siguiente código permite ajustar el "learning rate" dinámicamente durante el entrenamiento, disminuyendo cada vez que el "loss" no muestre una mejora.
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=2,
verbose=1,
mode='auto',
min_lr=0.000001)
early_stopping = EarlyStopping(
monitor='val_loss',
patience=10,
verbose=1,
mode='auto')
model_checkpoint = ModelCheckpoint(
filepath='weights.h5',
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=True,
mode='auto')Sin mas que agregar....Entrenemos! 😍
history = model.fit(train_it,
epochs=40,
steps_per_epoch=train_it.n//train_it.batch_size,
validation_data = test_it,
validation_steps=test_it.n//test_it.batch_size,
callbacks=[reduce_lr, early_stopping, model_checkpoint])Luego que el entrenamiento haga lo suyo debemos cargar los pesos, ya que el mejor modelo ha sido automáticamente guardado en el archivo "weights.h5"
model.load_weights('weights.h5')
model.save('pneumonia-chest-x-ray-cnn.h5')Validación del modelo
Hemos trabajado bastante, es hora de ver cómo ha resultado todo este esfuerzo...
Empecemos por mirar las gráficas históricas del "loss" y del "accuracy".
import sys
# plot diagnostic learning curves
def summarize_diagnostics(history):
# plot loss
plt.subplot(211)
plt.title('Cross Entropy Loss')
plt.plot(history.history['loss'], color='blue', label='train')
plt.plot(history.history['val_loss'], color='orange', label='test')
# plot accuracy
plt.subplot(212)
plt.title('Classification Accuracy')
plt.plot(history.history['accuracy'], color='blue', label='train')
plt.plot(history.history['val_accuracy'], color='orange', label='test')
plt.show()
plt.close()
summarize_diagnostics(history)
Se ven bien verdad ? 😀😀
Lo siguiente será hacer predicciones sobre los datos de validación y ver como se comporta nuestro modelo!
Antes de predecir debemos siempre hacer reset() sobre el conjunto que vamos a hacer la predicción.
val_it.reset() #reset val set
# Make prediction
pred=model.predict_generator(val_it,
steps=val_it.n,
verbose=1)
# optains class from probability prediction
predicted_class_indices=np.argmax(pred,axis=1)
# create label dictionary
labels = (val_it.class_indices)
labels = dict((v,k) for k,v in labels.items())
# apply labels dictionary over the predictions
predictions = [labels[k] for k in predicted_class_indices]
# Put the resul in fancy way
filenames=val_it.filenames
results=pd.DataFrame({"Filename":filenames,
"Predictions":predictions})

Vaya! parece que el modelo a logrado identificar correctamente los 16 casos de validación. 🥰🥰
Como último paso, y solo por mostrarles como se ve, jeje. Haré la matriz de confusión del resultado.
import seaborn as sns
def conf_matrix(matrix,pred):
class_names=[0,1] # name of classes
fig, ax = plt.subplots()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
# create heatmap
sns.heatmap(pd.DataFrame(matrix), annot=True, cmap="YlGnBu" ,fmt='g')
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
plt.show()from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(predicted_class_indices, val_it.labels)
conf_matrix(cnf_matrix,val_it.labels)
Gracias por leer, hasta pronto! 😊



Comments