
Como instalar Spark en tu Maquina Windows
- siria sadeddin

- Jun 6, 2020
- 3 min read
Hola! En este post les contaré como instalé Spark en mi maquina Windows. Estos días he estado trabajando con la extracción de datos desde bases de datos Oracle, y me dí cuenta que la simple conexión con la base de datos no era un método eficiente para la extracción de datos. La carga de millones de datos directamente sobre el entorno de trabajo de python no es lo mas recomendable para trabajar, y Spark es la herramienta perfecta para resolver este inconveniente, sin embargo, el proceso de instalación no es totalmente intuitivo así que les he querido mostrar como lo hice.

Apache Spark es un framework de computación en clúster open-source, proporciona APIs en Java, Scala, Python y R. También proporciona un motor optimizado que soporta la ejecución de grafos en general. También soporta un conjunto extenso y rico de herramientas de alto nivel entre las que se incluyen Spark SQL (para el procesamiento de datos estructurados basada en SQL), MLlib para implementar Machine Learning, GraphX para el procesamiento de grafos y Spark Streaming.
PASO 1: Pre-requisitos
Asegúrate de tener instalado java versión 8 o superior, de no tenerlo instalado. Para validar si tienes java entra a tu cmd y ejecuta java -versión. Si ya está instalado se mostrará un mensaje como el siguiente:

Windows 10
RAM: Al menos 4 GB
Espacio en Disco: 20 GB
PASO 2: Descargar Spark
Abre el siguiente link https://spark.apache.org/downloads.html

Haz clik en la parte señalada en rojo, te aparecerá la siguiente pagina. Da click en el link señalado y la descarga de Spark comenzará automáticamente.

PASO 3: Creación de la carpeta donde estará Spark
Lo primero que haremos es descomprimir el archivo descargado, tendremos que descomprimirlo 2 veces: de .tgz a .tar y de .tar a una carpeta descomprimida.
Una vez hecho esto, crearemos una carpeta con nombre "spark" en la dirección:
C --- Users ---Tu usuario
Por ejemplo:
C:\Users\Tu Ususario

Dentro de esta carpeta vamos a pegar los archivos que están en la carpeta que hemos descomprimido.

PASO 4: Modifica el archivo log4j.properties.template de la carpeta conf de spark :
Dentro de la carpeta spark que hemos creado ,en la carpeta conf, hay un archivo de nombre log4j.properties.template, lo abriremos con el notepad o wordpad y todas las partes donde aparece la palabra INFO la cambiaremos por la palabra WARN (INFO aparece 3 veces).
Además debemos modificar el nombre de todos los archivos contenidos en esta carpeta eliminando la parte .template como se muestra en la siguiente imagen.

PASO 5: Configuración de los Path
Ahora debemos configurar los path o archivos que hemos creado en el sistema. Para esto entramos a system--->Advanced system settings--->Enviroment variables

Vamos a crear una nueva variable de usuario llamada SPARK_HOME de valor C:\Users\Tu Ususario\spark

Luego editamos el system variables y añadimos una nueva variable (new) de valor %SPARK_HOME%\bin

PASO 6: Archivo winutils:
Necesitaremos descargar el archivo winutils para que Spark se ejecute correctamente, para esto entramos al link https://github.com/steveloughran/winutils/blob/master/hadoop-2.7.1/bin/winutils.exe
Descargamos el archivo .exe

Ahora vamos a crear una carpeta llamada winutils en el disco C y dentro otra carpeta llamada bin, dentro de esta carpeta dejaremos el archivo binutils.exe

Esta carpeta winutils también debemos incluirla en el path del sistema, nuevamente entramos a system--->Advanced system settings--->Enviroment variables y creamos la variable HADOOP_HOME de valor

luego agregamos %HADOOP_HOME%\bin al path

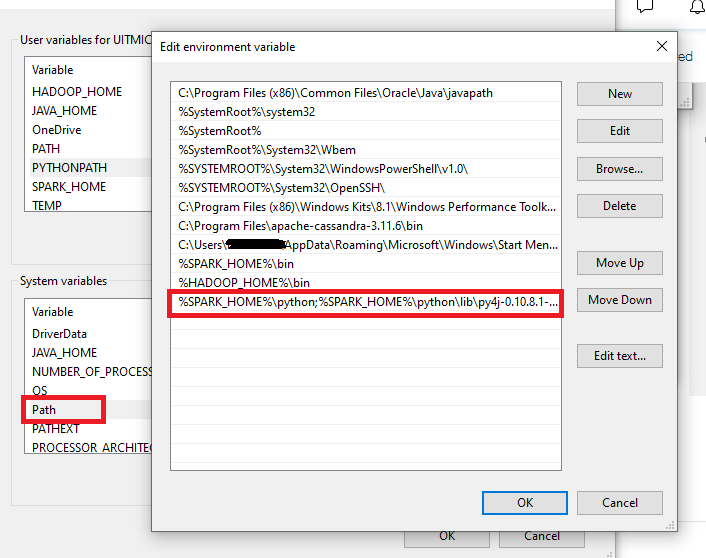
Para terminar la instalación debemos configurar las variables de PYTHONPATH con los valores
%SPARK_HOME%\python;
%SPARK_HOME%\python\lib\py4j-[BUSCA EN TU CARPETA LA VERSIÓN DEL ARCHIVO]-src.zip;
%PYTHONPATH%

y la añadimos también al path
PASO 7: Prueba
Ahora probaremos que Spark haya quedado bien instalado, entramos al cmd y escribimos spark-shell, debe aparecer un mensaje como el siguiente

Opcionalmente puedes correr las siguientes lineas de código y validar que no se genere ningún error.
val list = Array(1,2,3,4,5)
val rdd = sc.parallelize(list)
import spark.implicits._
val df = rdd.toDF("id")
df.show()

Eso es todo! espero que sea de utilidad
Hasta pronto! 🤗



Hola ! quiesiera saber si pudieras agregar como se llega a este punto %SPARK_HOME%\python\lib\py4j-[BUSCA EN TU CARPETA LA VERSIÓN DEL ARCHIVO]-src.zip;
dado a que no se como econtrar la version del archivo.
Muchas gracias!